TibetanHWR 系列三:CNN 训练与 Web 部署——手写识别在线演示实现
本文是 TibetanCharacter 系列的第三篇,也是终章。前两篇分别解决了「数据从哪来」和「数据怎么清洗」的问题,本篇把数据喂进模型,再把模型搬进浏览器。
项目资源
📊 数据集:百度网盘(提取码:
4ata)💻 项目代码:cairangxianmu/tibetan-hwr
🌐 Web 演示:cairangxianmu-tibetan-hwr.hf.space
一、整体架构
把「手写识别」拆成可以独立迭代的三个模块:数据、模型、服务。
dataset/ ImageFolder 组织的 PNG 集合 │ ▼recognition/ PyTorch 训练管线 ├── dataset.py DataLoader 工厂 + 字符映射表 ├── model.py DigitCNN / LetterCNN └── train.py 训练入口(日志 / 曲线 / 权重保存) │ ▼checkpoint/{mode}_best.pth │ ▼web/ FastAPI + Canvas ├── app.py 懒加载模型 · /predict 接口 └── static/ Canvas 画板 + 逐笔撤销两个任务走完全相同的管线,只由 --mode digit|letter 这一个开关切换数据源、模型结构和类别数。这让代码可以大部分共用,同时各自有针对性的设计。
二、模型设计
2.1 为什么要两个网络
| 数字 | 字母 | |
|---|---|---|
| 输入尺寸 | 28×28 | 64×64 |
| 类别数 | 10 | 30 |
| 图像面积 | 1× | 5.2× |
| 字形复杂度 | 简单 | 较复杂 |
字母任务的信息量(面积 × 类别)是数字任务的十几倍,共用一套小网络会欠拟合,共用一套大网络对数字又是浪费。因此按任务复杂度分别设计。
2.2 DigitCNN(10 类)
LeNet 风格,两层卷积 + 两层全连接,参数量 ~420K:
输入 1×28×28 Conv(1→32, 3×3, pad=1) → BN → ReLU → MaxPool(2) → 32×14×14 Conv(32→64, 3×3, pad=1) → BN → ReLU → MaxPool(2) → 64×7×7 Flatten → FC(3136→128) → ReLU → Dropout(0.5) FC(128→10)CPU 上单张推理 < 5 ms,训练 30 epoch 在笔记本上约 5 分钟。
2.3 LetterCNN(30 类)
在 DigitCNN 基础上增加第三个卷积块,并在每层卷积后加 BatchNorm,参数量 ~2.3M:
输入 1×64×64 Conv(1→32, 3×3) → BN → ReLU → MaxPool(2) → 32×32×32 Conv(32→64, 3×3) → BN → ReLU → MaxPool(2) → 64×16×16 Conv(64→128,3×3) → BN → ReLU → MaxPool(2) → 128×8×8 Flatten → FC(8192→256) → ReLU → Dropout(0.5) FC(256→30)BatchNorm 在这里做两件事:
- 加速收敛——实测达到相同验证准确率所需 epoch 数减少约 30%;
- 稳定训练——缓解内部协变量偏移,缩小训练 / 验证准确率差距。
两个模型都通过 get_model(mode) 工厂函数统一调用,训练、推理、权重加载全部复用同一套入口。
三、训练管线
3.1 数据加载
数据集按 ImageFolder 约定组织(子目录名即类别),通过 get_dataloaders() 一行获取 train/val DataLoader:
train_loader, val_loader, num_classes = get_dataloaders( mode="letter", # 或 "digit" batch_size=64, val_split=0.2, # 固定随机种子 42,保证划分可复现)3.2 预处理与数据增强
二值化预处理是训练和推理共用的第一步:对灰度图先做高斯模糊(σ=1),再用 Otsu 算法自动确定阈值进行二值化。相比直接 Otsu,模糊步骤先消除抗锯齿噪点,让笔画边缘更连续,实测效果明显优于多种其他方案(纯 Otsu、自适应阈值、形态学闭运算等)。
训练集在二值化前还施加几何增强,顺序很关键:几何变换必须在二值化之前做。若先二值化再做仿射变换,双线性插值会在纯 0/255 的图上产生灰色污染像素,破坏二值一致性。正确的流水线:
Grayscale → Resize → RandomRotation(±15°) → RandomAffine(translate=8%, scale=±15%, shear=±8°) → RandomPerspective(distortion=0.2, p=0.4) → GaussianBinarize(σ=1 + Otsu) → ToTensor → Normalize(0.5, 0.5) → RandomErasing(p=0.3) ← Tensor 级别,模拟笔画断裂fill=255 保证所有几何变换露出的区域为白色背景,与训练数据一致。
不做翻转。这一点专门针对藏文:多个字母互为镜像(如 ག / ད),水平或垂直翻转会直接污染标签。这是「通用视觉增强」在专门领域需要让位于先验知识的典型案例。
3.3 优化与调度
优化器:Adam,lr=1e-3,weight_decay=1e-4调度器:CosineAnnealingLR,T_max=epochs,eta_min=1e-6损失: CrossEntropyLoss(label_smoothing=0.1)早停: patience=10,验证准确率连续无改善时恢复最优权重并停止建议: digit → 30 epoch,letter → 50 epoch(batch 128)标签平滑(label_smoothing=0.1)让模型对自己的预测不过度自信,缓解在小数据集上的过拟合。
早停监控验证准确率,连续 patience 个 epoch 无改善时触发,并自动恢复精度最高时的权重——既防止过拟合,又省去手动盯训练曲线的麻烦。训练结束或早停后,每隔 5 个 epoch 的周期检查点也会保留最近 3 个,便于回退。
Cosine 退火的直觉:前期大 lr 快速下降到低损失盆地,后期小 lr 精细探索盆底,避免在最优解附近震荡。相比 StepLR,在同等 epoch 下通常能多挤出 0.5–1 个百分点。
3.4 日志与可视化
每次训练在 runs/{mode}_{timestamp}/ 下自动生成四件套:
| 文件 | 用途 |
|---|---|
args.json | 超参数快照 + 原始命令,复现实验 |
metrics.csv | 逐 epoch 指标,便于后处理分析 |
events.out.* | TensorBoard 事件文件 |
training_curves.png | 训练结束时的总览图 |
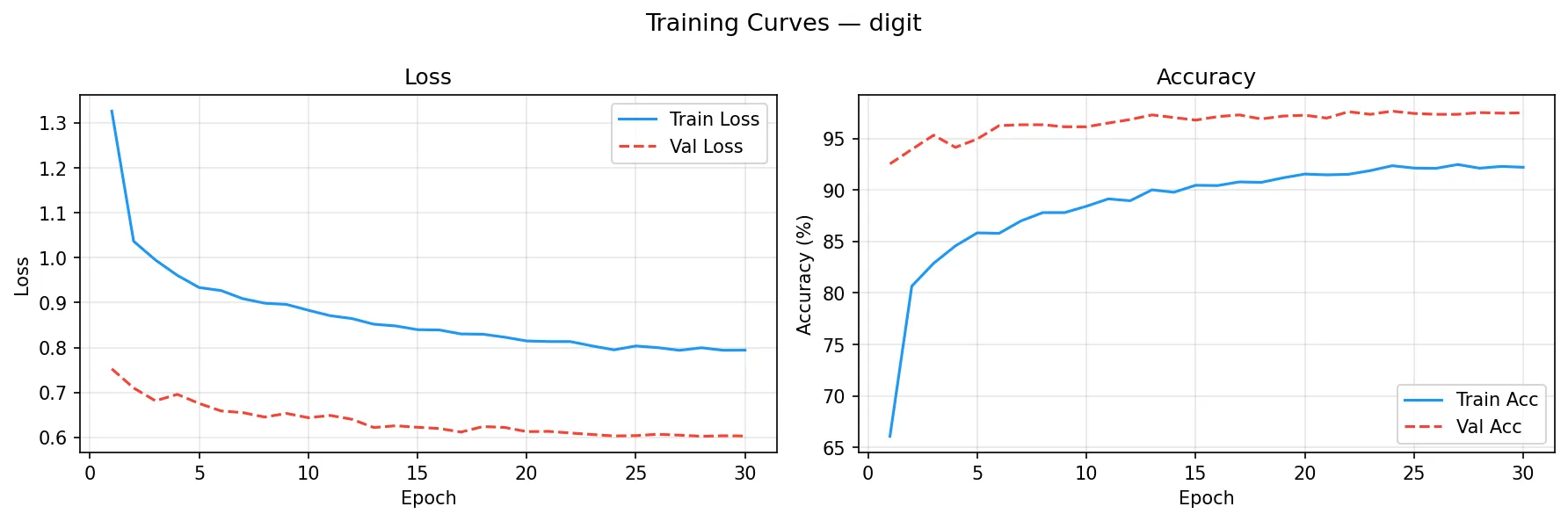
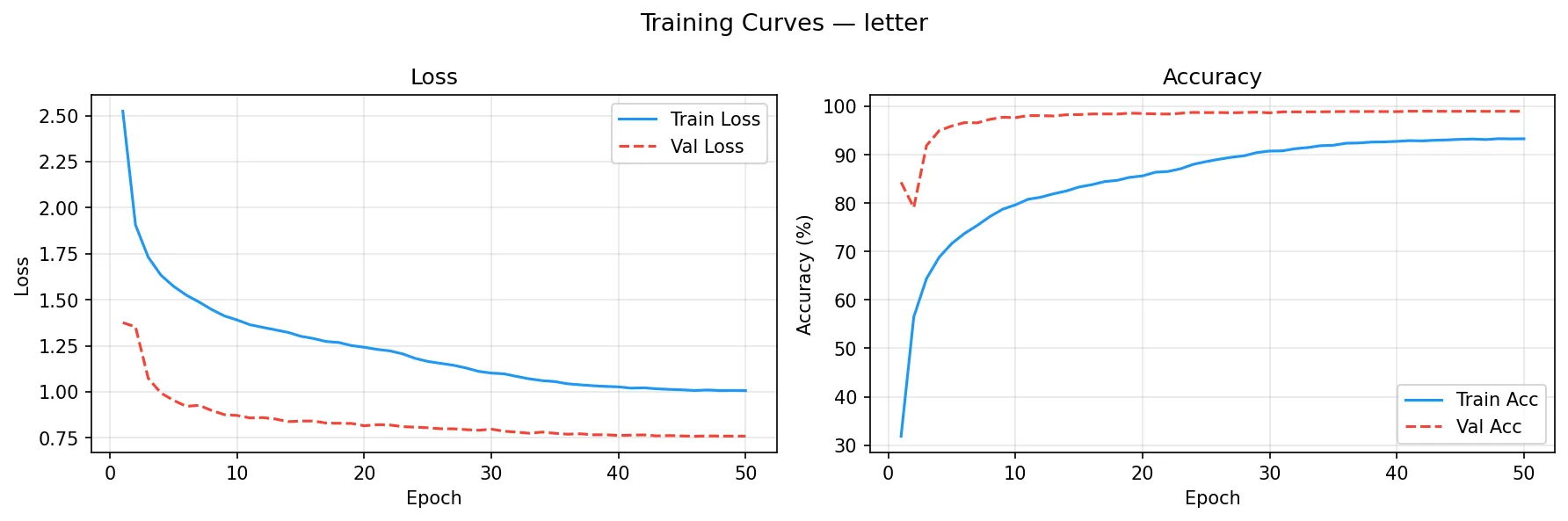
训练结束后自动生成训练曲线(Loss / Accuracy):
数字模型(30 epoch)
字母模型(50 epoch)
3.5 权重保存
不止保存权重,还把元数据一起存进 checkpoint,让推理侧加载时无需再传参:
torch.save({ "epoch": epoch, "mode": args.mode, # "digit" / "letter" "num_classes": num_classes, "model_state_dict": model.state_dict(), "val_acc": val_acc,}, "checkpoint/{mode}_best.pth")四、Web 在线演示
4.1 后端:FastAPI + 懒加载
三个路由就够了:
| 路由 | 方法 | 说明 |
|---|---|---|
/ | GET | 返回前端页面 |
/health | GET | 健康检查,返回推理设备 |
/predict | POST | 接收 base64 图像 + 模式,返回识别结果 |
模型懒加载是一个值得单独提的设计:服务启动不触碰权重文件,首次收到某模式请求时才读盘加载,之后缓存在内存中。好处是启动秒级响应、内存占用按需增长;如果只识别数字,字母模型永远不会被加载。
_model_cache: dict = {}
def _load_model(mode: str) -> torch.nn.Module: if mode in _model_cache: return _model_cache[mode] checkpoint = torch.load(ckpt_path, map_location=_device) model = get_model(mode, num_classes=checkpoint["num_classes"]) model.load_state_dict(checkpoint["model_state_dict"]) model.eval() _model_cache[mode] = model return model4.2 前端:Canvas + 逐笔撤销
前端不依赖任何框架,核心是一个 400×400 的 Canvas。鼠标和触屏统一处理,真正想讲的是 逐笔撤销的实现——不存像素,而是存每一笔落笔前的快照:
function startDraw(e) { // 落笔前拍快照 currentStroke = ctx.getImageData(0, 0, canvas.width, canvas.height); ctx.beginPath(); ctx.moveTo(x, y);}
function endDraw() { strokeHistory.push(currentStroke); // 抬笔后入栈}
undoBtn.addEventListener("click", () => { const prev = strokeHistory.pop(); ctx.putImageData(prev, 0, 0); // 还原到上一笔之前});这样任意笔画数都能无损撤销,且实现比维护笔画向量列表简单得多。代价是内存占用随撤销栈线性增长,对小画板无伤大雅。
其它交互细节:
- 图片上传(点击 / 拖放),自动居中缩放填充画板;
Ctrl+Z撤销、Enter识别;- 切换数字 / 字母模式时清空画板。
识别请求就是把 Canvas toDataURL 编码为 base64 发过去,响应体携带 Top-5 候选:
{ "label": 3, "character": "༣", "confidence": 97.42, "top5": [ {"label": 3, "character": "༣", "confidence": 97.42}, {"label": 8, "character": "༨", "confidence": 1.83}, ... ]}4.3 关键细节:训练—推理分布对齐
这是本项目调试中收益最高的一步,值得单独拎出来讲。
上线后首轮体验识别率很低。原因是:训练样本里字符几乎铺满整帧(28×28 或 64×64 都是紧贴字符边缘),但推理时用户在 400×400 画板上写一个字,字符只占中心一小块,周围大片白边。直接缩放,字符就被压成了一小坨,模型从未见过这种尺度。
解决办法:在推理预处理里先做紧边界框裁剪,再缩放。流程图:
Canvas 400×400(白底 + 一小块字符) │ ▼ _tight_crop:找暗像素边界框 → 扩 15% padding → 裁剪 → 填充为正方形字符铺满帧的图像 │ ▼ Grayscale → Resize(28×28 或 64×64) ▼ GaussianBinarize:高斯模糊(σ=1)→ Otsu 二值化 ▼ ToTensor → Normalize(0.5, 0.5)模型输入(与训练验证集分布一致)核心代码:
def _tight_crop(img_gray, pad_ratio=0.15): arr = np.array(img_gray) mask = arr < 200 # 暗像素掩码 rows, cols = np.any(mask, 1), np.any(mask, 0) if not rows.any(): # 画板为空 return img_gray
rmin, rmax = np.where(rows)[0][[0, -1]] cmin, cmax = np.where(cols)[0][[0, -1]] pad = max(4, int(max(rmax - rmin, cmax - cmin) * pad_ratio)) # 外扩 padding 后裁剪,不越界 ... cropped = img_gray.crop((cmin, rmin, cmax + 1, rmax + 1)) # 填充为正方形白背景,避免后续 Resize 拉伸 side = max(cropped.size) square = Image.new("L", (side, side), 255) square.paste(cropped, ((side - cw) // 2, (side - ch) // 2)) return square加入这一步后,识别率显著提升。经验:训练和推理的数据分布不一致,即使模型本身没问题也会表现得「模型很差」——定位这类问题比调模型本身更重要。手写画板和上传图片走同一条预处理路径,保证两种输入的表现一致。
五、快速上手
# 1. 依赖pip install -r requirements.txt
# 2. 下载预训练模型(推荐)# 从 GitHub Releases 下载 digit_best.pth 和 letter_best.pth,放入 checkpoint/# https://github.com/cairangxianmu/tibetan-hwr/releases/latest
# 3. 启动 Web 服务cd webuvicorn app:app --port 8000# 浏览器打开 http://localhost:8000,书写或上传图片后点击「识别」如需自行训练(需先准备数据集,见系列一):
cd recognitionpython train.py --mode digit --epochs 30 # ~5 min CPUpython train.py --mode letter --epochs 50 --batch-size 128 --patience 10 # ~5 min GPU六、小结
本篇把数据变成了一个可交互的 Demo,沿途的关键选择:
- 按任务复杂度差异化设计模型:DigitCNN 与 LetterCNN 均含 BatchNorm,LetterCNN 额外多一层卷积块,避免一刀切;
- 预处理统一二值化:高斯模糊(σ=1)+ Otsu,训练与推理完全一致;几何增强必须在二值化之前做,否则插值会污染二值图;
- 增强策略服从先验:藏文镜像字禁用翻转;增加透视变换和随机擦除以拟合手写板的书写风格;
- 标签平滑 + 早停:防止小数据集过拟合,无需手动盯训练曲线;
- 懒加载服务:启动快、内存按需增长,适合多模型共享后端的场景;
- 训练—推理分布对齐:Canvas 空白多、训练样本铺满帧,靠
_tight_crop拉平差距,实测收益最高。
三篇合在一起,完整覆盖了这套系统数据采集(系列一)→ 图像预处理(系列二)→ 模型训练与在线演示(本篇) 的全链路。没有用到任何预训练模型,从零开始、轻量部署,可作为理解手写识别端到端链路的入门实践。
文章分享
如果这篇文章对你有帮助,欢迎分享给更多人!
评论区
音乐
暂未播放